

OpenSLO, Operators, Benchmarks, Obervability e um pouco mais...
OpenSLO, Operators, Benchmarks, Obervability e um pouco mais...
Voltamos nessa bagaça

Opa! Bão? Estive um pouco ausente, troquei de trabalho recentemente e precisei me dedicar um pouco mais que o normal pra absorver muita informação, então precisei sacrificar algumas coisas pra manter tudo saudável. Mas enfim, estamos de volta com os artigos mais malandros e safadinhos que correram na minha timeline durante a semana! Bora lá?
A comunidade de SRE anuncia o projeto de specs de SLO, o OpenSLO

“Assim como o papel crucial que o Docker desempenhou na padronização do formato do contêiner, e que o Helm desempenhou na padronização do gerenciamento de pacotes do Kubernetes - o OpenSLO está trazendo um formato comum para a definição de Service Level Objectives”
Vamos começar com uma iniciativa muito legal da comunidade, iniciada por algumas pessoas de peso do mercado de engenharia de confiabilidade, o OpenSLO (Site do Projeto). O projeto visa criar especificações de level de serviço entre diversas camadas de infraestrutura e aplicação. O projeto ainda está embrionário e durante a SLOConf, a comunidade e as big techs foram intimadas a contribuir com as especificações. Tá ai um cara pra gente começar a olhar com mais carinho. Segue aqui o Github do pessoal.
Vou deixar o link do artigo aqui pra vocês com mais detalhes
Benchmark entre Linkerd e Istio
Como disse meu amigo Bruno Padilha, vulgo Padz, o importante não é saber se Linkerd é melhor ou não que o Istio, mas a importância de se preocupar com Benchmarks e testes de carga em cenários reais.
Esse post no blog da Linkerd é um Follow Up de um outro blogpost feito em 2019 pela empresa Kinvolk no qual comparava o desempenho das duas alternativas de Service Meshes. Desde aquele post, o Linkerd demonstrava uma performance muito maior que a do Istio, exceto por 1 métrica, o consumo de recursos do Data Plane. Nesse atualizado, comparando as duas versões mais recentes das duas alternativas, sendo Linkerd 2.10.2 e Istio 1.10.0, o Linkerd ja demonstrou resultados melhores nisso também.
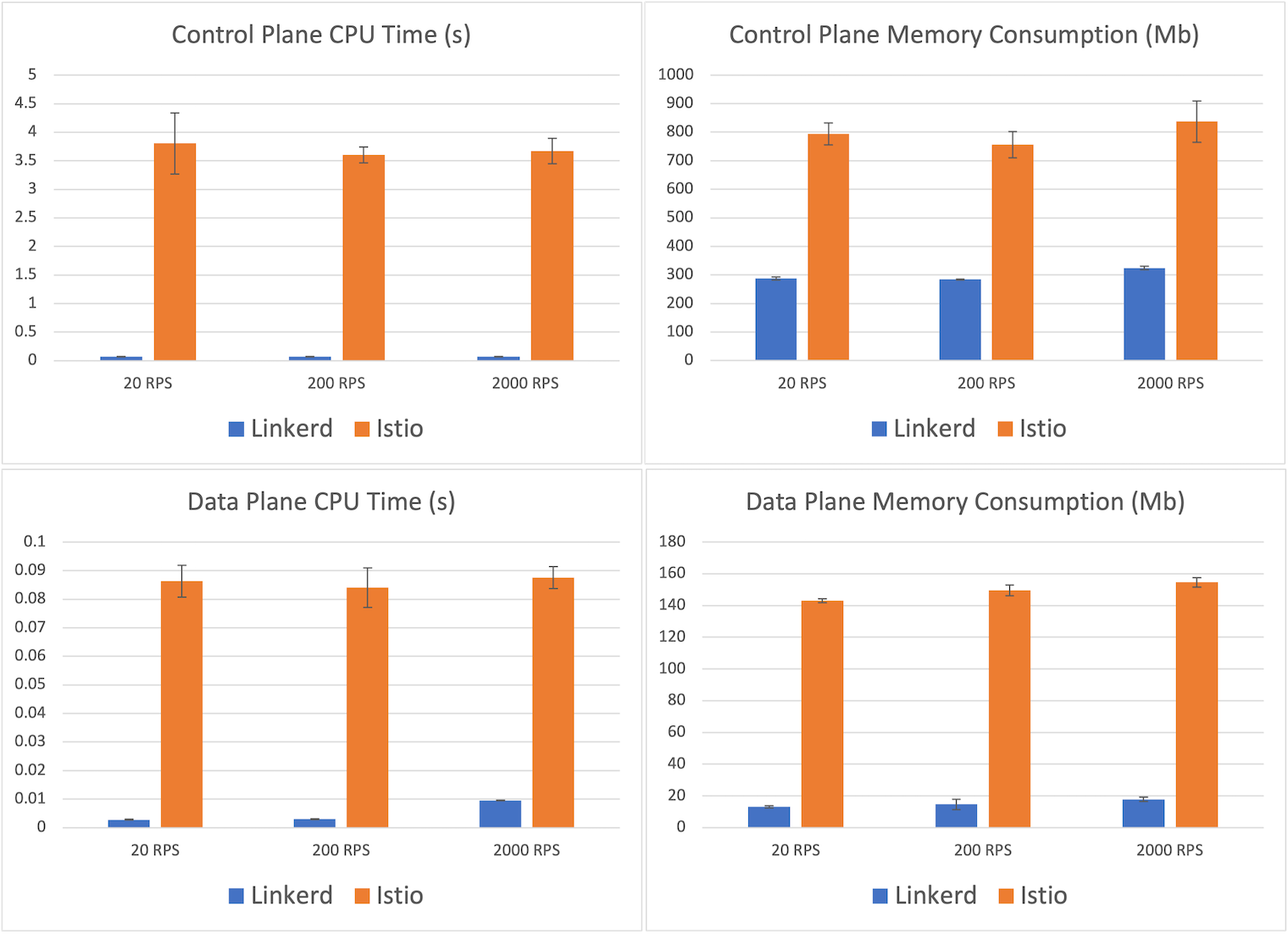
Os cenários de teste foram os mesmos para as duas alternativas, sendo eles:
Ambos possuindo trafego mTLS habilitados
Ambos coletando métricas L7
Ambos com log level INFO
Ambas adicionando retry, fallback e controlar o trafego perfeitamente
Sem features multicluster habilitadas
Segue o post pra vocês darem uma analisada no teste por completo.
Correlacionando dados de Observability de forma eficiente, uma jornada braba...
Um post super didático sobre correlação de indicadores de observabilidade, em diferentes níveis de captura e agregação, como logs, metricas e tracing . Sempre que começamos a jornada de observability é extremamente complexo decidir o que medir, e quando medir. E tão comum quanto selecionarmos milhares de dimensões tornando as coisas menos monitoraveis ainda, afinal quando tudo é importante, nada é realmente importante. Quando temos muitos alarmes que não requerem ações, paramos de acompanhar os alarmes, quando temos muitos logs inúteis, paramos de olhar os logs, quando temos muito gráficos só por ter, paramos de olhar os gráficos, afinal se você não tem o beneficio de um NoC na sua empresa, você raramente vai trabalhar olhando dashboards...
Esse artigo escrito pelo Bartek Płotka, da um roadmap bem bacana e insights pra elevar a maturidade de observação do seu projeto. Vou deixar aqui pra você dar uma olhada.
Desenvolvimento de Kubernetes Operators na Prática

Um assunto que está na minha lista de pesquisa aqui pra esse segundo semestre é ficar afiado na confecção de CRDs e Operators. Tive oportunidade de me introduzir nesse assunto pra resolver alguns problemas mas notei vários gaps que preciso cobrir pra fazer isso da melhor forma possível. A maioria dos Operators poderia ser um script? Claro que sim. Mas se todo mundo pensasse assim, teriamos o ecossistema cloud native que temos hoje? Claro que não...
Esse artigo exemplifica varios exemplos de estrutura e vários e algumas boas praticas na confecção de operators e o bootstrap do kubebuilder.
Dê um liga que se for do seu interesse, é um how to bem completo.
Flash cards de estudo pra CKAD? Tem tbm garai

A cobertura que rolou da Kubecon garantiu um voucher pra galera, e eu comprei a prova da CKAD por fazer mais sentido pro meu momento. Comecei um scrapping de artigos e materiais de estudo (aceito dicas) e encontrei esse cara aqui...
Quando me preparo pras provas da AWS, eu costumo adotar a estratégia de Flash Cards, tava procurando coisas do tipo aqui pra introduzir no meu dia a dia e encontrei esse cara aqui pra fabricar os meus iniciais. É um conjuntinho de perguntas e respostas que podem ajudar quem está começando a quebrar o gelo para a prova. Recomendo, são 150 questões.
Armadilhas comuns no uso de Infraestrutura como Código
Numa realidade de trabalho cada vez mais cloud native, um projeto sem IaC hoje é quase dificil de se encontrar por ai, e como qualquer padrão, a adoção pode ser uma curva custosa e longa pra adaptar a todos os cenários possíveis de uma empresa ou projeto. Por mais que IaC seja talvez o padrão mais maduro e mais "plug and play" que temos, em larga escala ainda é difícil e custoso, e existem algumas armadilhas que podemos cair no processo, como diz o sábio Não Sei Quem Disse Isso Pela Primeira Vez, aprender com o erro alheio é sempre uma boa estratégia... Esse artigo cita alguns dos erros mais comuns na adoção de alguma ferramenta / processo de IaC. Recomendo a leitura a todos.
Me sigam no Twitter pra acompanhar meu feed (e varias treta) mais de perto!
Até mais pessoal!