![[Feed]elissauro by @fidelissauro](https://substackcdn.com/image/fetch/$s_!XxRY!,w_80,h_80,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2Fe1bdebbc-5dab-42b9-b64e-16c81c435282_400x400.png)

![[Feed]elissauro by @fidelissauro](https://substackcdn.com/image/fetch/$s_!XxRY!,w_36,h_36,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2Fe1bdebbc-5dab-42b9-b64e-16c81c435282_400x400.png)
Perdão pelo vacilo, Karpenter, Koo, Eleições e Resposta a incidentes
Já peço perdão pelo vacilo, agora bora ler uns negocio aqui

Então, pelo menos eu pedi desculpa. Hoje de manhã acordei com a intenção de voltar pra sua caixa de entrada como se nada tivesse acontecido e é exatamente assim que vai acontecer.
Depois de ser duramente criticado por várias pessoas por parar com uma das melhores coisas que já fiz na internet, eu decidi voltar aqui pra repassar os melhores artigos que caíram no meu feed durante a semana.
Então pra gente não perder a dinâmica de ser direto e reto, vamos começar! E nada melhor pra começar do que um jabá gostoso né galera.
Essa newsletter ficou juntando poeira por alguns longos meses mas o pai não ficou parado não. Ta achando que eu vivo de festa? (gostaria)
Karpenter - Provisionando um Cluster de EKS sem Node Groups

Nesses pouquíssimos artigos técnicos que eu escrevi pra comunidade esse ano, 100% deles foram sobre o Karpenter.
Eu venho estudado a ferramenta pra poder dar algumas soluções criativas pra alguns problemas não convencionais de escalabilidade. Assim bem surtado mesmo. Foda-se.
O primeiro artigo-jabá que eu vou colocar na lista é uma Prova de Conceito que deu certo até demais, onde propus um ambiente de EKS sem Node Groups, levando toda a responsabilidade de suprir capacidade computacional do cluster pro Karpenter e protegendo os recursos importantes do cluster da volatilidade do Karpenter, como kube-system utilizando Fargate Profiles.
A ideia do Karpenter como tecnologia, comparado com seu antecessor espiritual o cluster-autoscaler, é prover um scale in / out de uma maneira “just in time”. Tiramos métricas bem interessantes dele dos casos de uso propostos.
Ta liberadissimo dar aquele bizu.
E como toda PoC, teje o projeto do Github.
Karpenter - Estratégias para resiliência no uso de spot instances em produção

Falando de Karpenter, vamos falar um pouco mais de Karpenter.
Nesse segundo artigo, apresentei algumas estratégias interessantes pra ganhar resiliência operacional utilizando Spots em produção no seu cluster de EKS..
As estratégias apresentadas nesse artigo são focadas nas ferramentas providas pelo Karpenter, mas seu conceitual pode ser aplicado pra literalmente qualquer workload AWS que se propõe a utilizar spot instances.
Abordamos alguns pontos interessantes como:
Multi-AZ
Diversificação de famílias
Diversificação de tamanhos
Diversificação de On Demand x Spot
Se puderem dar aquela moralzinha, segue o link
Kubernetes Capacity Planning

Cara, peço perdão aos navegantes mas vou falar um pouquinho mais de Kubernetico, mas agora vou deixar aqui uma ferramenta muito interessante pra fazer Capacity Planning no Kubernetes.
O Kubernetes Instance Calculator te permite planejar a alocação de pods de forma eficiente. Você oferece os requests e limits médios dos Deployments e dos Daemonsets que você pretende alocar e ele te permite testar opções de qual tamanho vai te fazer mais eficiente em performance, custo ou disponibilidade, depende do que você está buscando no momento.
Não existe uma bala de prata sobre como utilizar Kubernetes, nem a sobre A Melhor Estratégia de Alocação de Todos os Tempos então é melhor aceitar que onde vocês passar perguntas perguntas como:
“Menos nodes maiores ou mais nodes menores?”
“Qual a quantidade máxima de pods que eu posso ter por node?”
“Qual o melhor tamanho de máquina pra custo x beneficio?”
vão ocorrer diversas vezes, e sempre vão existir respostas diferentes pra elas,
Já deixo esse artigo interessante aqui também, sobre como escolher o seu node size.
Como as eleições presidenciais afetam a internet?
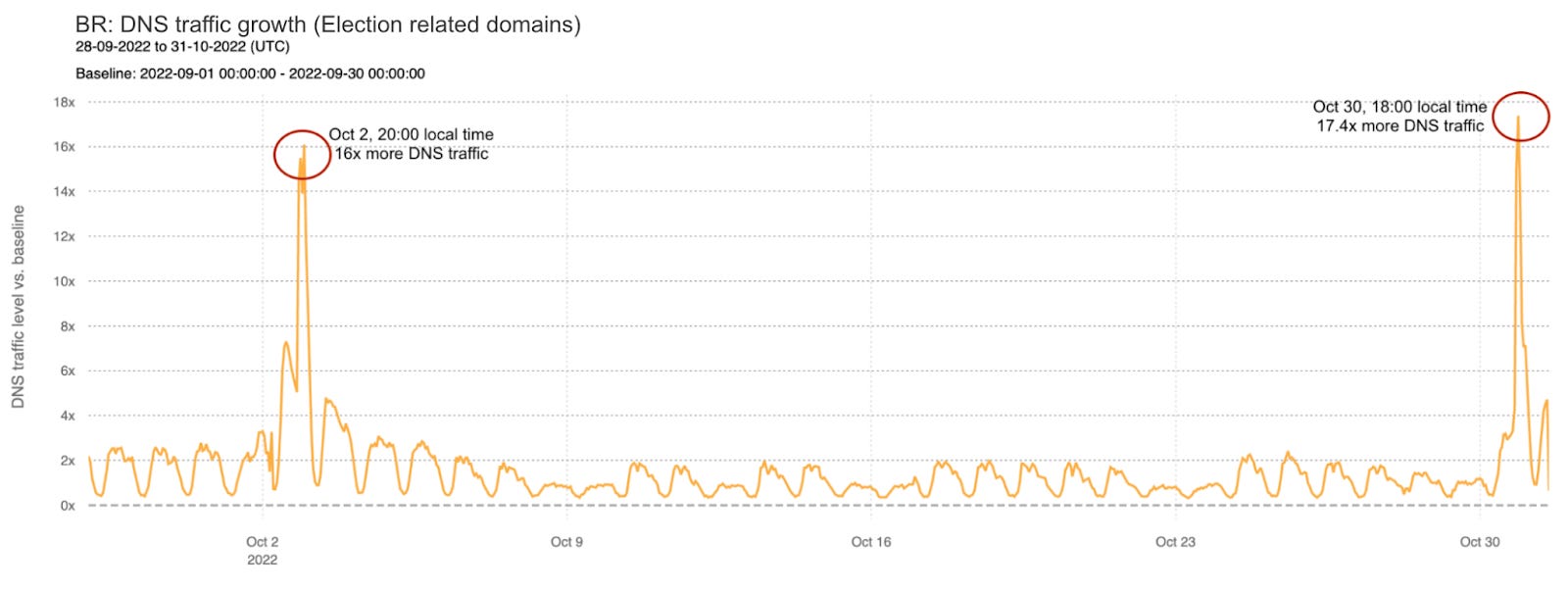
Aqui veio um artiguinho muito bom da Cloudflare, feito pelo João Tomé, mostrando um caso interessante das mudanças que ocorreram no comportamento “normal” da internet durante as eleições presidenciais no Brasil, exemplificando como os “Eventos do Mundo real” impactam a internet.
O artigo usa dados da Cloudflare pra mostrar estatísticas interessantes pra análisar o comportamento durante o primeiro e segundo turno.
O fenômeno de ter um trafego muito menor durante o dia, no qual existe a teoria de que são as pessoas fora de casa, indo votar.
O uso maior de dispositivos móveis na internet durante os eventos.
Aumento gritante em consultas de DNS durante no período pré, durante e pós apuração nos domínios referentes aos candidatos.
Aumento de tráfego nos sites de notícia, possivelmente nos que estavam veiculando os resultados em tempo real.
Algumas métricas para medir o sucesso do DevOps no seu produto

Aqui também vai um artiguinho legal apresentando 17 métricas para medir o sucesso do DevOps durante o desenvolvimento de software da sua empresa / produto.
A gente que é muito técnico, as vezes é fácil medir coisas relacionadas a performance, problemas, comportamento, recursos, networking, disponibilidade e os caraio, e eu tenho o sentimento que é meio natural ignorar outros tipos de indicadores de produtividade do processo por considerar eles como “métricas superfulas”. Mas a vida ensina que não é bem assim né, e uma hora ou outra ela vai te dar uma lição de moral a respeito disso, com um pedaço de pau na mão.
O artigo apresenta possibilidade do que pode ser medido durante seu ciclo de CI/CD, como:
DORA Metrics (Frequências de Deploy, Tempo de implantação, tempo para restaurar o serviço, porcentagem de deploys que causam problemas em produção)
Cycle Time
Lead Time
Qualidade referentes a vulnerabilidade, style guides, cobertura de teste, quebra de definições arquiteturais.
Métrica de CI como falhas, tempo médio, Flakiness, sucessos e etc.
Recomendo legal o artigo, dêem aquele liga
Se divirta feito um idiota comigo: Correlação espúria

Pow cara, eu tenho que compartilhar que eu estou felizão de voltar a estudar de forma acadêmica. Escolhi um MBA em Data Science e Analytics e está sendo revigorante estudar as coisas que eu não sei nem por onde começar.
E como eu to sendo introduzido em um mundo novo, já aviso que vai em vários momentos aparecer materiais de Data aqui a partir de agora. Começando por um rolê engraçadinho, sobre correlação espúria.
Correlação espúria é uma relação meramente estatística que existe entre o comportamento e observação de duas variáveis, mas onde não existe uma relação de causa e efeito entre elas, ou tem alguma terceira variável misteriosa não conhecida.
Esse site mostra diversas correlações espúrias, começando com essa do exemplo onde mostra a correlação entre o número de pessoas que se afogadas em piscinas vs o número de filmes em que o Nicolas Cage aparece kkkkkkkkkkk.
Eu fiquei igual um imbecil rindo desses casos. Eu acho que alguém, nem que seja 1 pessoa, vai se divertir também.
Amazon EKS agora suporta Kubernetes na versão 1.24
Agora foi lançado oficialmente o suporte da versão 1.24 do Kubernetes para o EKS. Já está tudo ok e funcionando. Fiz alguns testes mas nada produtivo até o momento. Quando estiver, pode deixar que eu comunico.
Importante ressaltar que a versão 1.24 do Kubernetes possui alguns highlights, como o fim do suporte do Dockershim, abraçando de vez o containerd como Runtime.
Veja o changelog completo para o EKS.
Jornada do time de Resposta a Incidentes do LinkedIn

O time de Segurança da Informação do Linkedin publicou um post bem interessante detalhando a jornada da reformulação do processo de resposta a incidentes da plataforma.
É um case bem completinho mostrando alguns desafios, ferramentas e indicadores que foram usados pra reconstruir tudo, achei bem interessante pelo motivo de todo o pipeline ser orientado a dados e se portar como “plug n play” para a jornada de software.
Eu tenho a opinião que esse é o papel dos times de operações no ciclo de vida do produto. Não gerar overhead, ser o maximo transparente possível, automatizar tudo e principalmente ser participativo e não imperativo no processo. Maior problema de 99% dos times de segurança do planeta segundo minha humilde opinião.
Vou deixar o case aqui pra vocês lerem no banheiro. Confia.
Golang e Queues
Pra não dizer que eu não lembro da galera de Golang que veio parar aqui nesse humilde jornalzinho nerdola, vou deixar aqui uma lista de libs de Go que estão com o desenvolvimento e suporte ativos para trabalhar com Queues e tarefas assíncronas e distribuídas. Algumas bem interessantes como Asynq, Taskq e Machinery (embora esse não me pareça estar tão ativo assim)
Eu não vou mentir pra tu não dizendo que eu testei alguma delas, pq eu não tive tempo ainda. Mas se eu salvei nos meus favoritos, com certeza eu vou testar um dia. Na próxima insônia ,talvez. Enquanto eu não enjoar de Stardew Valley que é meu crack do momento**.** Um dia próximo para esse humilde fazendeiro.
Detalhe importante
Entrem no canal do Telegram onde eu envio os links pra fazer a curadoria depois, tá embrionário ainda e é a primeira vez que eu divulgo isso. Então se você gosta de ler coisinhas todos os dias, eu jogo tudo lá antes de sentar e decidir o que vai vir aqui pra cá
E já me segue nas redes sociais se não tiver ainda
Chave Pix pra você me pagar um café: fe60fe92-ecba-4165-be5a-3dccf8a06bfc
Playlist que eu escutava enquanto escrevia essa Weekly: